
0
Bekeken


Laatst geupdate op

De Wayback Machine is het meest populaire onderdeel van de Internet Archive-website. De gratis online tool, die voor het eerst werd geïntroduceerd in 2001, laat je "terug in de tijd" gaan om te zien hoe websites er wereldwijd uitzagen. De Wayback Machine beschikt over 562 miljard webpagina's op het moment van schrijven, en elk jaar worden er nog veel meer toegevoegd.
Hier is een blik op de Wayback Machine en wat het speciaal maakt.
Het internetarchief, gemaakt door Brewster Kahle en Bruce Gilliat, is een non-profitorganisatie met als missie "universele toegang tot alle kennis". Vanaf het begin, de organisatie heeft gratis openbare toegang geboden tot gedigitaliseerd materiaal, zoals webpagina's, boeken, audio-opnamen, inclusief liveconcerten, video's, afbeeldingen en software programma's.
Tot op heden beslaat alles wat door het internetarchief wordt verzameld meer dan 70 Petabytes serverruimte, inclusief twee exemplaren van alles. De organisatie wordt gefinancierd door middel van donaties, beurzen en vergoedingen van diensten voor het digitaliseren van boeken. Voor privacy houdt het internetarchief de IP-adressen van zijn lezers niet bij en gebruikt het overal het HTTPS-protocol (beveiligd).
Slechts een deel van het internetarchief, de Wayback Machine, is ontworpen om website-inhoud vast te leggen die is gewijzigd of verwijderd. Sinds de lancering is het een van de meest populaire en erkende plaatsen op internet geworden. Kahle en Gilliat noemden de site naar het fictieve tijdreizende apparaat in de animatieserie uit de jaren 60, The Rocky and Bullwinkle Show.
Hoewel Internet Archive de site pas in oktober 2001 voor het publiek lanceerde, begon de Wayback Machine vanaf mei 1996 met het archiveren van webpagina's in de cache. Tot 2001 bewaarden digitale banden informatie die alleen toegankelijk was voor geselecteerde wetenschappers en onderzoekers. Toen alles vijf jaar later live ging voor het publiek (zoals al lang gepland was), had het al meer dan 10 miljard gearchiveerde pagina's bevat.
Tegenwoordig bewaart de site historische webgegevens op een cluster van Linux-knooppunten. De Wayback Machine downloadt alle openbaar toegankelijke informatie en gegevensbestanden op webpagina's via zijn crawlmechanisme. Niet alles wat op een website wordt gepost, is hier echter opgenomen, aangezien sommige inhoud beperkt is of is opgeslagen in databases die niet toegankelijk zijn. Hierdoor worden sommige websites beter gecrawld dan andere, afhankelijk van hoe ontwikkelaars tegelijkertijd een site hebben gemaakt.
U zult ook opmerken dat hoe nieuwer het archief is, hoe meer inhoud er beschikbaar is voor een bepaalde site. Een nieuwe tool die het Internet Archive in 2005 introduceerde, is een van de redenen waarom nieuwere gegevens vollediger zijn. Archive-It.org helpt inconsistenties in gedeeltelijk gecachte websites te overwinnen door instellingen en makers van inhoud in staat te stellen verzamelingen digitale inhoud te oogsten en te bewaren.
Webcrawlers, ook wel spider of spiderbot genoemd, zijn zo oud als het internet zelf. Deze crawlers zijn internetbots die continu op internet surfen voor indexeringsdoeleinden, waardoor ze een belangrijk onderdeel van elke moderne zoekmachine zijn. De crawlers die worden gebruikt voor de Wayback Machine om digitale snapshots van websites te maken, zijn afkomstig van verschillende bronnen, die in de loop van de tijd zijn veranderd.
Zoals u snel zult merken, varieert de frequentie van het vastleggen van momentopnamen sterk per website. Doorgaans geldt dat hoe groter (en misschien wel populairder) een website is, hoe meer er wordt gecrawld. Bovendien hangt veel af van hoe vaak een website paginawijzigingen heeft. Zelfs de kleinste websites worden uiteindelijk gecrawld, tenzij er een reden is dat dit niet het geval is. Met een wachtwoord beveiligde sites worden bijvoorbeeld niet gecrawld, en evenmin als websites waarvan de site-eigenaren hebben gevraagd dat ze niet worden opgenomen.
De Wayback Machine-website is voor iedereen gemakkelijk te gebruiken. Om historische momentopnamen van een website te vinden, typt u de naam in de zoekmachine van de site. Op de pagina met zoekresultaten geven hyperlinks de datums en tijden aan waarop een site is gearchiveerd. Klik op de link om de site "terug in de tijd" te zien.
In de volgende voorbeelden ziet u de voorpagina van de Apple-website die is opgenomen in februari 2005 en november 2014, en de homepage van CNN vanaf een datum in maart 2004 en september 2010.
Opmerking: deze crawls bevatten ook links naar andere pagina's zoals vastgelegd op de opgegeven datums, niet alleen de startpagina's.
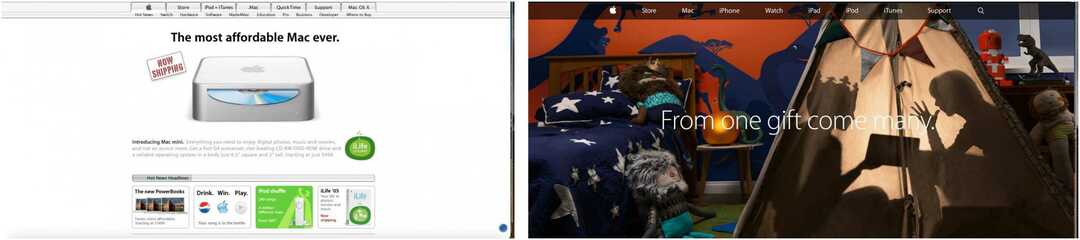
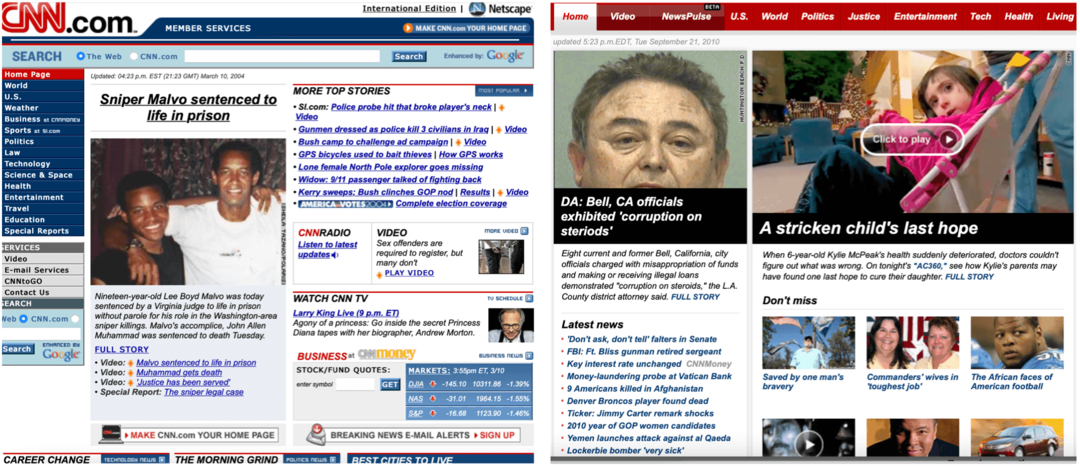
Gemaakt voor zowel onderzoekers als het publiek, heeft de Wayback Machine een paar ingebouwde tools die incidentele gebruikers misschien missen. Zo zijn pagina's met zoekresultaten bijvoorbeeld zo ontworpen dat ze gemakkelijk te raadplegen zijn. Zoals uitgelegd: “Als u een gearchiveerde pagina vindt waarnaar u op uw webpagina of in een artikel wilt verwijzen, kunt u de URL kopiëren. Je kunt zelfs fuzzy URL-overeenkomsten en datumspecificatie gebruiken... maar dat is wat geavanceerder. "
Met de Wayback Machine kunnen site-eigenaren ook een functie "Pagina nu opslaan" gebruiken om een specifieke pagina op te slaan. En toch is het niet perfect. Momenteel voegt de functie de site-URL niet toe aan toekomstige crawls. Bovendien slaat het verzoek niet meer dan één pagina op. Het is echter een goede eerste stap om de startpagina van uw website te archiveren voor historische gegevens.
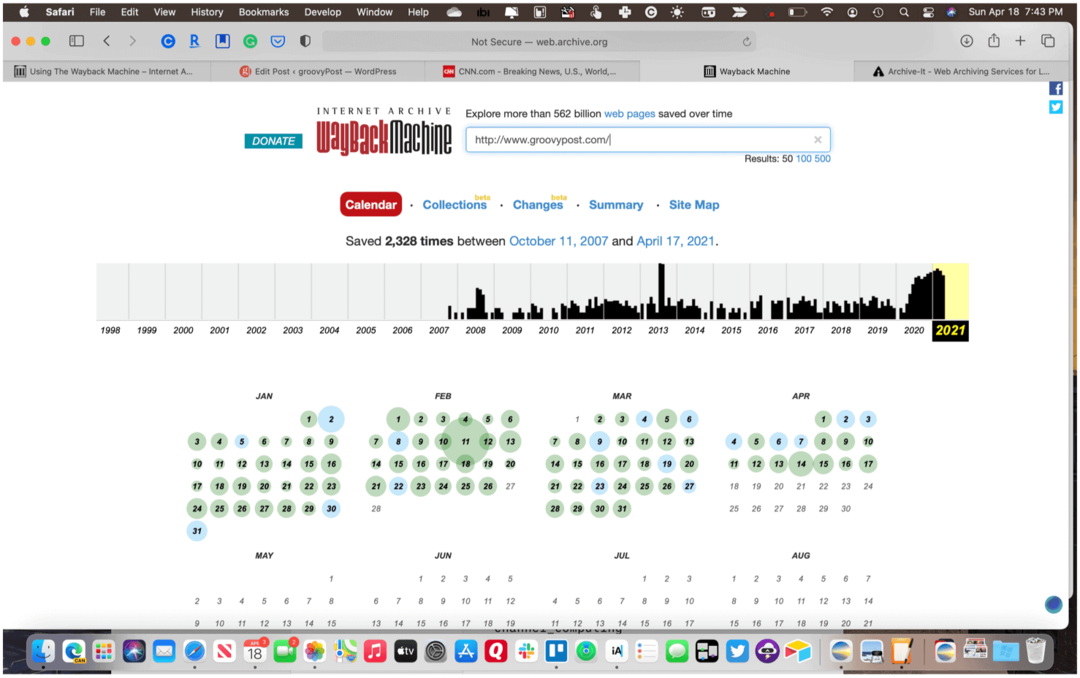
U hoeft de Wayback Machine niet elke keer te bezoeken om een nieuwe zoekopdracht uit te voeren. In plaats daarvan kunt u inhoud zoeken door het adres in de werkbalk van uw webbrowser in te voeren. Gebruik dit formaat voor alle zoekopdrachten: http://web.archive.org/*/www.yoursite.com/*. Gebruik bijvoorbeeld http://web.archive.org/*/www.groovypost.com/* om gearchiveerde pagina's voor de GroovyPost!
Ten slotte bevindt de Wayback-machine zich niet alleen via internet. U kunt een Wayback Machine-app vinden voor iOS en Android. Er zijn ook extensies voor Chrome, Safari en Firefox. Ontwikkelaars zullen ook de Internet Archive Wayback Machine-API's willen bekijken. Deze maken het gemakkelijker voor ontwikkelaars om informatie over Wayback-opnamegegevens op te halen.
De Internet Archive Wayback Machine ondersteunt verschillende API's. Door dit te doen, wordt het gemakkelijker voor ontwikkelaars om informatie over Wayback-opnamegegevens op te halen.
"Terug in de tijd" gaan voor uw favoriete websites is de nr. 1 reden om de Wayback Machine te bezoeken. Het is ook een geweldige tool voor iedereen die websitegeschiedenis onderzoekt voor schoolprojecten of zakelijk gebruik. Wat je ook doet, bezoek de Wayback Machine en kijk wat je kunt ontdekken in een paar eenvoudige stappen.
Ga voor meer informatie over de Archive-It-abonnementsservice van het Internet Archive naar het officiële website en begin vandaag nog met bijdragen!
